
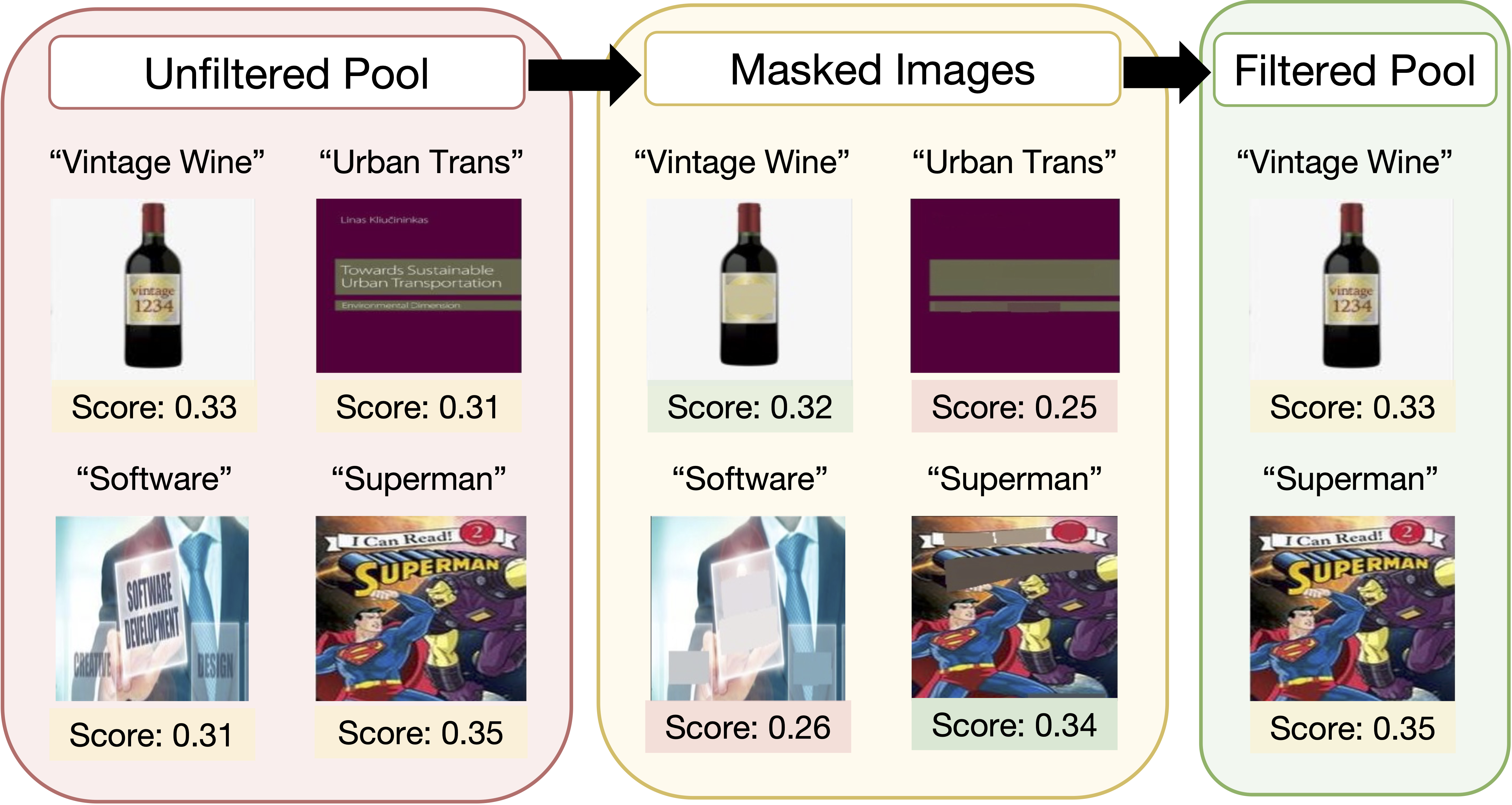
On various data pool sizes from 2M to 64M shows that the accuracy gains enjoyed by T-MARS linearly increase as data and compute are scaled exponentially.
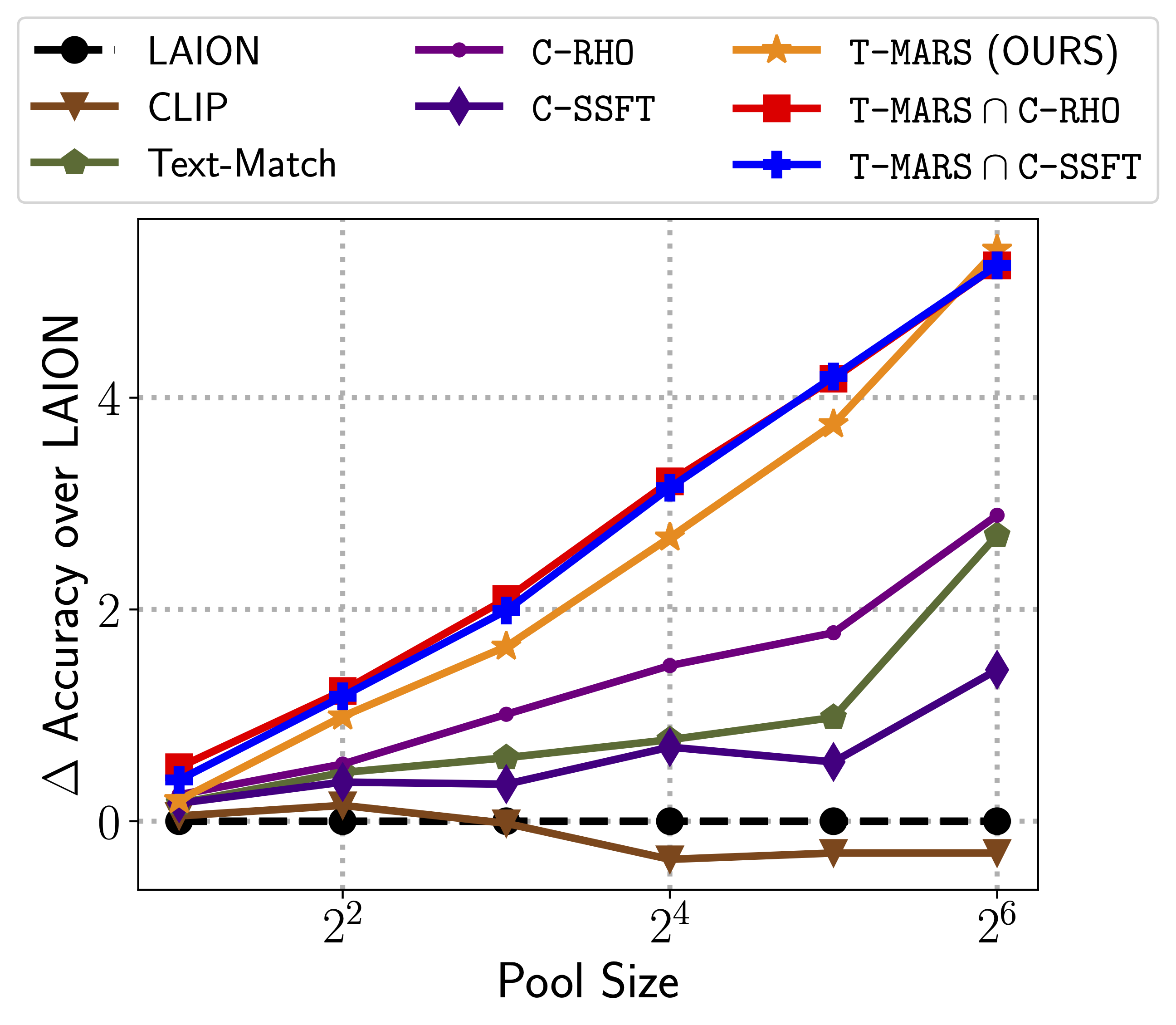
T-MARS outperforms the top-ranked method on the “medium scale” of DataComp (a data filtering benchmark) by a margin of 6.5% on ImageNet and 4.7% on VTAB.
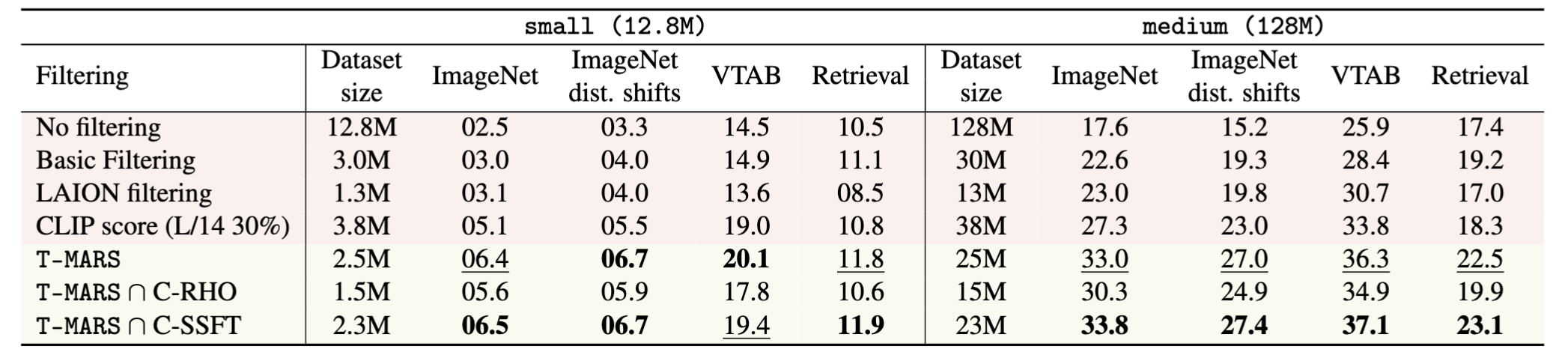
Zero-shot accuracies for various filtering strategies on the small and medium pools of the DataComp benchmark. ∩ denotes the intersection between two filtering strategies. T-MARS outperforms the state-of-art on DataComp by a margin of 5% on the medium scale (ImageNet).
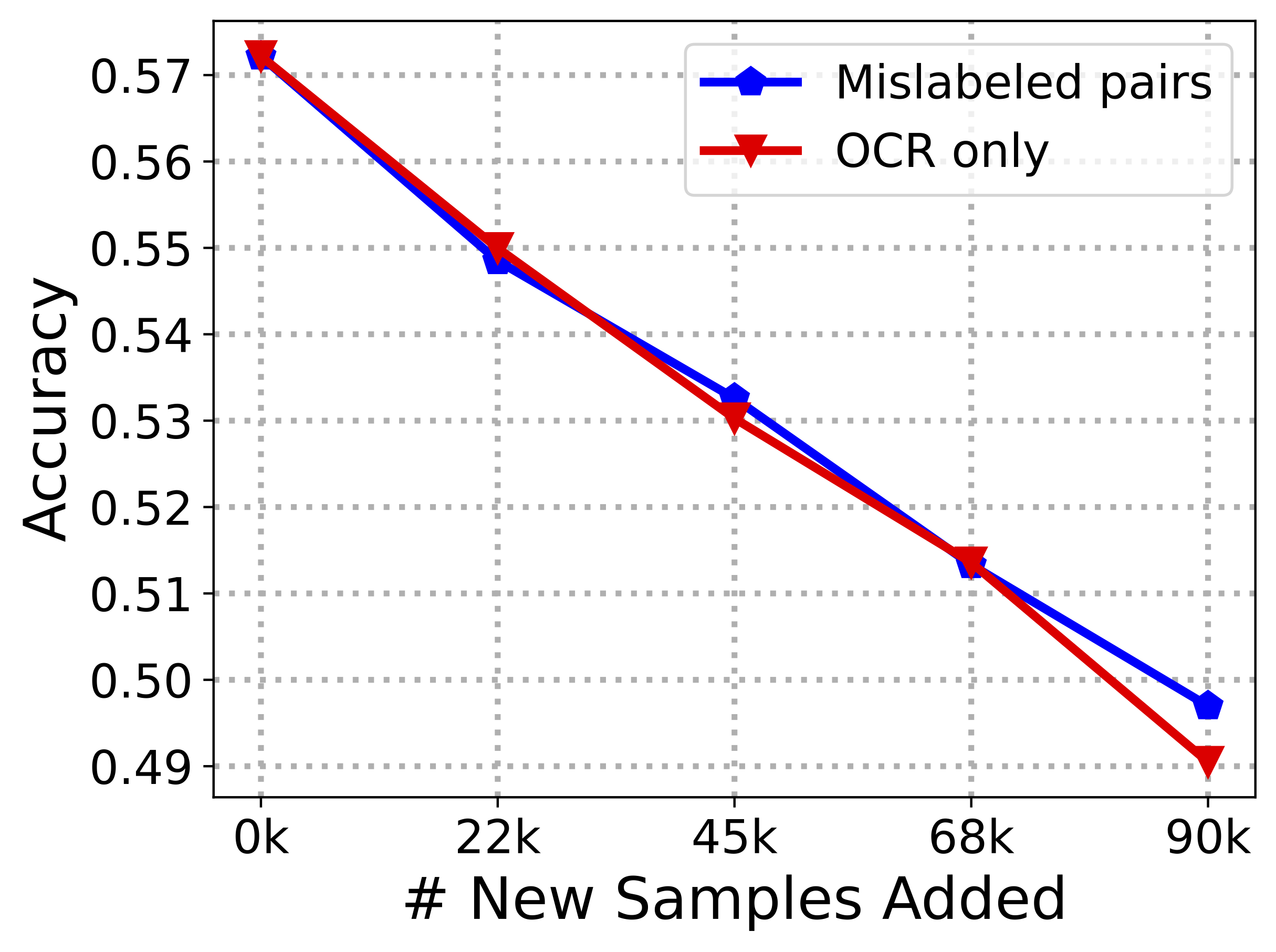
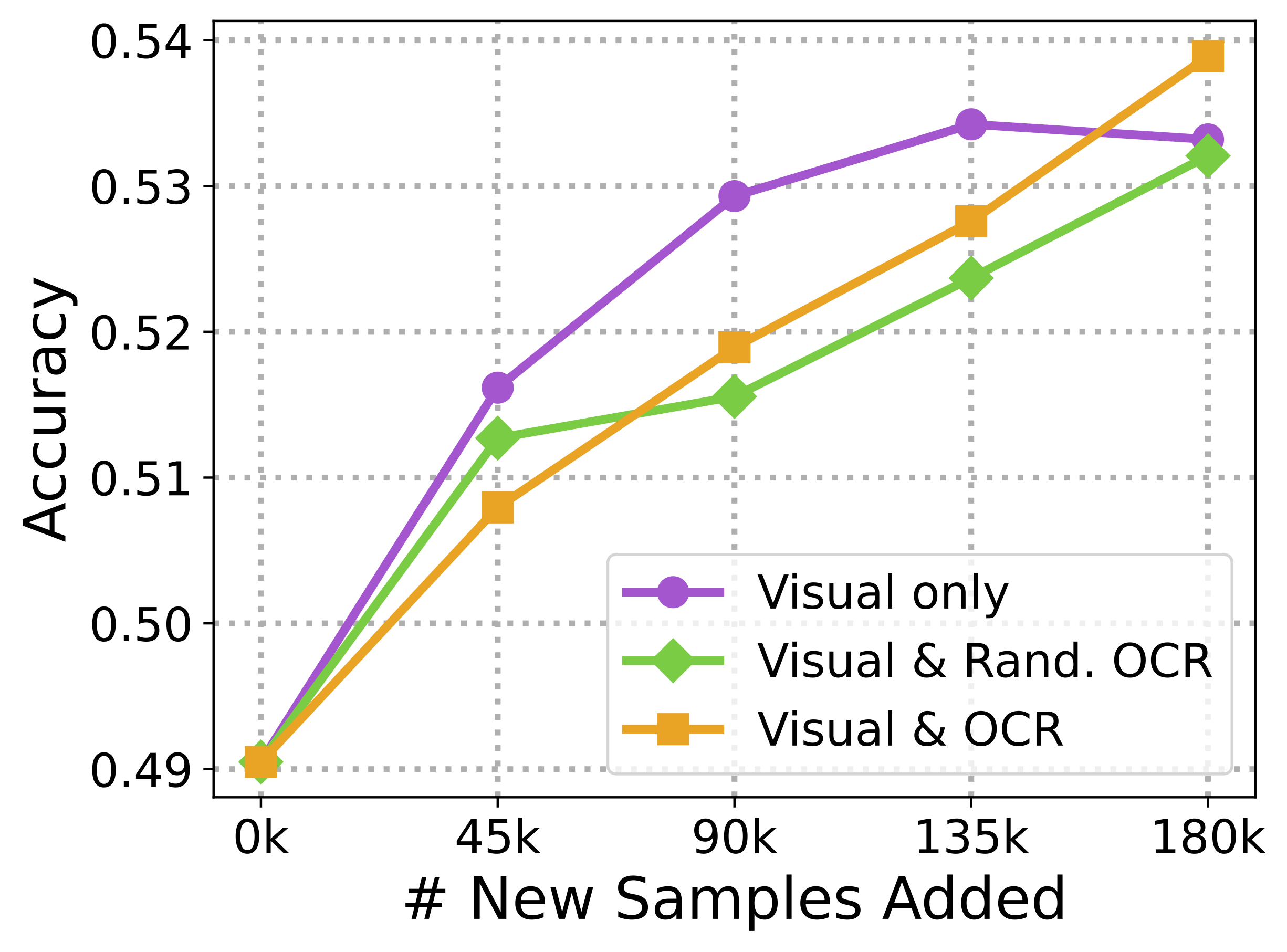
We investigate the utility of various data types in LAION. Images with text as the only predictive feature hurt the model as much as adding mislabeled examples to the dataset!! Images with both visual & text features are as useful as those with no text & should not be removed!